Корпоративные данные проходят сложный путь между OLTP, аналитическими витринами OLAP, средами Data Lake и слоями Data Warehouse. Значительная часть этого пути строится вокруг ETL-процессов, которые регулируют извлечение, преобразование и загрузку информации. От качества этих процедур зависит то, насколько корректно предприятия используют данные в аналитике и прикладных сервисах.
Инженеры всё чаще подчёркивают, что эффективность аналитики опирается не только на выбранную архитектуру, но и на устойчивость интеграционных цепочек.
В этой статье мы подброно рассмотрим природу ETL, разберём применение в корпоративных средах и узнаем, как устроен современный ETL-пайплайн и какие инструменты используют команды разработки.
- Что такое ETL-процессы
- Расшифровка
- Простыми словами
- В программировании
- Пример
- Системы ETL
- Informatica PowerCenter / IDMC
- Microsoft SSIS
- Talend Data Integration
- Apache Airflow
- Modus ETL
- Где используются ETL-процессы
- Базы данных
- Data Warehouse (DWH)
- OLAP и OLTP
- Большие данные (Big Data)
- Аналитика
- Облачные технологии
- IoT
- Машинное обучение (ML)
- Что такое ETL-пайплайн
- Разработка ETL-процессов
- Инструменты ETL
- Для корпоративного ПО
- Облачные (SaaS)
- С открытым исходным кодом (Open-source)
- Пользовательские
- ETL и ELT: в чём разница?
- Заключение
Что такое ETL-процессы
Извлечение, преобразование и загрузка (ETL) — это процесс обработки данных, который объединяет информацию из разных источников в единую структуру. Данные собираются из файлов (CSV, JSON, XML и др.), реляционных и NoSQL-баз данных (PostgreSQL, MS SQL Server, MySQL, MongoDB…), систем и приложений, после чего очищаются от ошибок и приводятся к согласованному формату. После этого они загружаются в централизованное хранилище (DWH, Data Lake, Data Hubs), где становятся доступны для анализа и построения отчетов в BI-, CRM- и EPM-системах.

Процесс обеспечивает упорядочивание и стандартизацию информации, позволяя работать с большими объемами данных без потери качества. ETL интегрирует различные источники данных (БД, файлы, облачные приложения, события), создавая целостное и удобное для обработки представление информации.
В результате данные становятся управляемыми и структурированными, повышается их точность и готовность ко всевозможным аналитическим задачам.
ETL превращает разрозненные данные в единый поток для анализа и обоснованных решений. Вместо ручного поиска и сопоставления данных организации получают структурированный набор, готовый к отчетности, прогнозированию и аналитике.
Расшифровка
ETL — аббревиатура от английских слов Extract, Transform, Load, переводится как «Извлечение, Преобразование, Загрузка». Каждый этап выполняет конкретную функцию в работе с данными, обеспечивая их качество и готовность к аналитике.
- Извлечение (Extract). На этом этапе данные собираются из различных источников: реляционных и NoSQL-баз данных, файловых систем, облачных сервисов, API приложений, сенсорных устройств и логов. Цель — получить исходную информацию без потери контекста, независимо от формата и структуры источника.
- Преобразование (Transform). Данные проходят очистку, проверку на корректность, фильтрацию, объединение и агрегирование. Включает стандартизацию форматов, расчет новых показателей, проверку бизнес-правил и устранение дублирующихся записей. Результат — согласованная и готовая к анализу информация.
- Загрузка (Load). Обработанные данные помещаются в целевые системы: хранилища данных (DWH), аналитические платформы, витрины данных (Data Marts) или корпоративные базы для отчетности. На этом этапе формируется единый поток информации, который сразу можно использовать для построения отчетов, дашбордов и прогнозных моделей.
Простыми словами
Если проще, ETL — это комплекс процедур, который собирает данные из разных источников, очищает их и превращает в структурированную, готовую к использованию информацию для аналитики и BI-систем.
В программировании
ETL в программировании выполняет автоматическое перемещение и обработку данных между различными системами. Он объединяет информацию из баз данных, API, файловых хранилищ и облачных сервисов в единый формат, упрощая сопоставление типов данных и согласование структур.
Для работы с ETL в программировании используют:
- Системы ETL: корпоративные, облачные и open-source платформы, которые автоматизируют извлечение, трансформацию и загрузку данных, позволяют создавать, управлять и мониторить пайплайны.
- Языки программирования: Python, SQL, Java, Scala, R — применяются для написания скриптов, запросов и алгоритмов обработки данных, интеграции с различными источниками и масштабируемой работы с большими объемами информации.
- Среды разработки: визуальные конструкторы пайплайнов, скриптовые среды, интеграционные платформы, среды для тестирования и отладки процессов ETL.
- Типы систем для загрузки и хранения: Data Warehouse для структурированных аналитических данных, Data Lake для хранения больших объёмов сырых данных, OLAP/OLTP-решения для аналитики и оперативной обработки транзакций, интеграционные витрины данных для конкретных бизнес-процессов, распределённые хранилища и облачные платформы для масштабируемости.
- Потоки и оркестрация: автоматизация перемещения и трансформации данных, управление последовательностью операций, планирование и мониторинг ETL-процессов, уведомления о сбоях и логирование для анализа и аудита.
- Дополнительные инструменты и подходы: средства профилирования и контроля качества данных, библиотеки для работы с большими данными, технологии потоковой обработки, кэширование и буферизация для оптимизации производительности.
Пример
Как пример рассмотрим процесс обработки результатов спортивных соревнований в формате CSV.
Исходные данные часто разрозненные: имя и фамилия спортсмена, клуб, город, возрастная группа, время заплыва могут храниться в одной строке или разбросаны по разным колонкам. ETL собирает эту информацию, очищает её и приводит к единому формату, готовому для анализа и загрузки в базу данных.
На этапе извлечения данные берутся из внешнего источника — CSV- или Excel-файла, базы данных или веб-приложения.
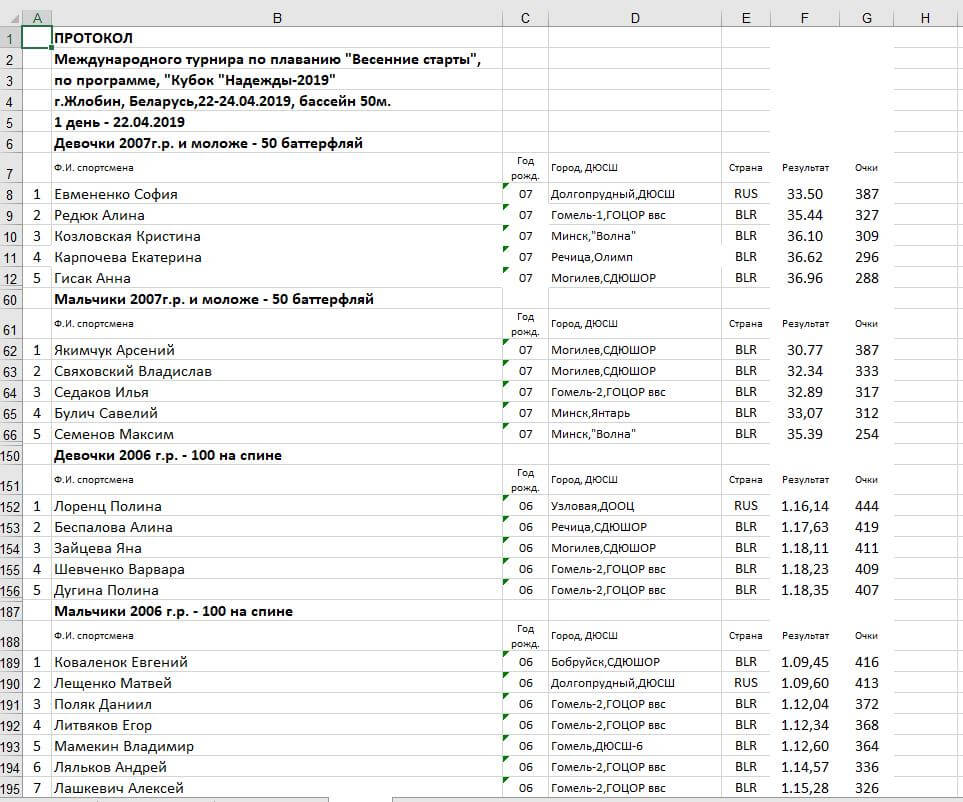
Архитектура ETL в данном случае сосредоточена на первичной подготовке данных (ETL 1). На этом этапе создается стейджинговая (т.е. промежуточная с точки зрения целевой модели) таблица, а перед её заполнением проводится data profiling — анализ исходных данных для понимания их структуры и качества.
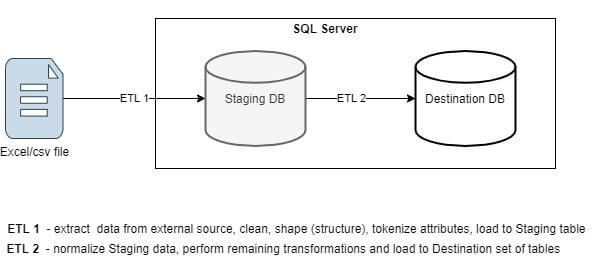
Основные шаги data profiling включают:
- Оценку метрик исходных данных: перечень атрибутов, их типы, длину текстовых полей, возможность пустых значений (null/not null), потенциальные ключи и соответствие целевым атрибутам.
- Выявление аномалий: пропущенные или «грязные» данные, множественные значения в одной ячейке и прочие несоответствия.
- Определение способов парсинга: подходы к обработке и разбору данных для корректной загрузки в таблицу.
Стейджинговая (Staging) таблица служит промежуточным хранилищем, где данные очищаются, структурируются и готовятся к полноценному ETL-процессу.
Требования к Staging-ETL (v1.0) показывают, что исходные данные часто содержат множественные значения в одной колонке — например, «Фамилия+Имя», «Клуб+Город», «Группа+Длина дистанции+Стиль».
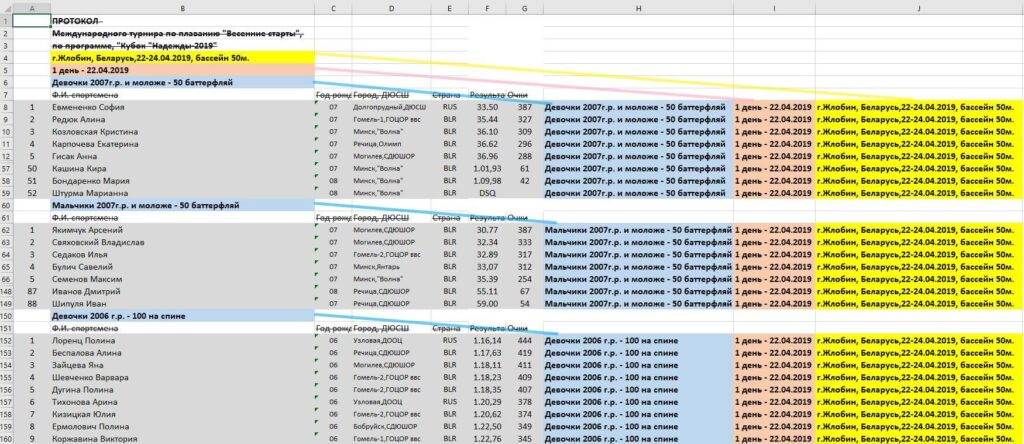
Такие записи не готовы к прямой загрузке в целевые таблицы, поэтому перед трансформацией необходима детальная сверка исходных данных с целевыми атрибутами и уточнение правил разбиения и нормализации.

Для загрузки «сырых» данных создаём «рабочую» таблицу в базе данных — загружаем данные в БД, а затем выполняем очистку и трансформацию.
После загрузки выполняется первичный анализ с помощью CTE-модулей (временных таблиц), например, для извлечения списка возрастных групп и дисциплин. В процессе выявляются аномалии, например, нарушенный порядок строк, объединённые поля или пропущенные заголовки. Эти особенности требуют доработки логики парсинга перед полной трансформацией и загрузкой в целевые таблицы.

Этап преобразования включает разделение фамилии и имени, нормализацию дат и чисел, разбор сложных полей на отдельные компоненты, фильтрацию дубликатов и приведение всех данных к единым правилам. Например, время заплыва может быть записано как 44.1, 42,35 или 1.09,98 — ETL разбивает его на часы, минуты, секунды и миллисекунды, а строки с дисквалификацией (DSQ) выделяются отдельно, чтобы результат стал структурированным и пригодным для аналитики.
На этапе загрузки обработанные данные перемещаются в целевое хранилище — Data Warehouse или Data Lake. Там формируется единый поток информации для BI-систем, отчетов и прогнозных моделей, обеспечивая автоматизацию процессов и прозрачность данных.
Системы ETL
Рассмотренный выше пример обработки спортивных результатов показал, как можно вручную организовать ETL-процесс: данные извлекаются из CSV-файла, очищаются и трансформируются с помощью SQL-запросов, а затем загружаются в базу данных. Ручная обработка данных подходит для учебных задач или небольших наборов информации, но требует значительных усилий при масштабировании и работе с комплексными источниками в организациях.
Ручной ETL — как сборка пазла по кусочкам: весело, пока деталей мало, но с ростом данных каждый пропущенный кусочек превращается в головоломку.
Для автоматизации подобных процессов применяют специализированные ETL-системы. Они обладают самым разным по сложности функционалом — от простого переноса и очистки данных до сложных трансформаций и интеграций с аналитическими платформами. В основе большинства решений лежит low-code- или no-code-конструктор, похожий на инструменты BPM-систем: потоки формируются визуально, блоки соединятся логикой, а настройка параметров не требует глубокого программирования.
Informatica PowerCenter / IDMC
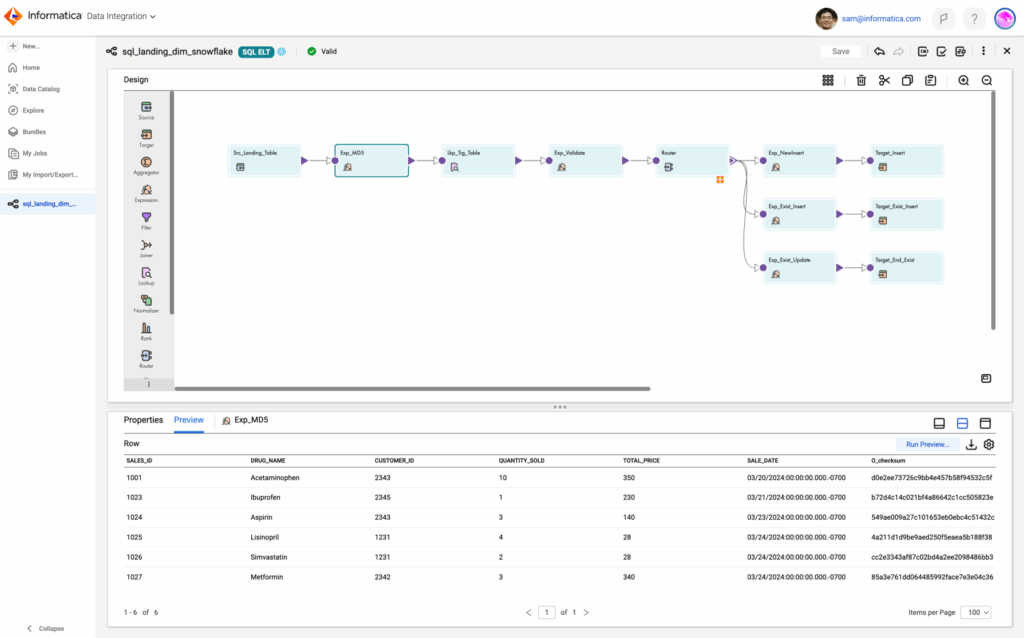
Informatica PowerCenter относится к классическим корпоративным ETL-платформам, которые используют серверную архитектуру и централизованное управление метаданными. Система обеспечивает стабильную обработку больших объёмов данных, поддержку сложных трансформаций, расписаний и оркестрации. PowerCenter часто применяют там, где нужно строго контролировать качество, версии и безопасность, включая банковский сектор и крупные промышленные организации.
Informatica IDMC (Intelligent Data Management Cloud) работает как облачная платформа, объединяющая интеграцию, качество и управление данными. В её основе лежит движок CLAIRE, который анализирует метаданные, выявляет ошибки, автоматизирует каталогизацию и оптимизирует преобразования. Поддерживается широкий спектр источников: базы, файлы, SaaS-сервисы, облачные хранилища и потоковые системы. Визуальный конструктор и библиотеки готовых трансформаций помогают быстро собирать сложные цепочки обработки.
Обе платформы часто применяются совместно в гибридных ландшафтах: PowerCenter отвечает за стабильные серверные интеграции внутри корпоративного контура, а IDMC — за облачные источники, масштабирование и автоматизацию управления данными.
Microsoft SSIS

Microsoft SSIS (SQL Server Integration Services) — инструмент интеграции данных, встроенный в экосистему SQL Server и ориентированный на разработку управляемых, воспроизводимых ETL-процессов. Среда разработки работает на базе Visual Studio, где пакеты собираются визуально, а логика выполнения формируется через поток управления.
Обработка данных охватывает реляционные СУБД, файловые структуры, облачные хранилища и корпоративные сервисы. Потоки данных наполняются трансформациями любого уровня сложности: от базовой очистки и агрегации до сопоставления структур и подготовки аналитических наборов. При необходимости логика дополняется пользовательскими скриптами, что делает SSIS пригодным для гибридных и нестандартных задач.
Инфраструктура SSIS разворачивается через SSIS Catalog, где удобно хранить версии пакетов, управлять параметрами и отслеживать выполнение. Каталог даёт полный контроль над историей запусков, ошибками и конфигурациями, поэтому команды быстро локализуют сбои и поддерживают прозрачный цикл обновлений. SQL Server Agent берёт на себя расписания и автоматизацию пайплайнов: ночные загрузки, оркестрацию зависимостей, ретраи и почтовые нотификации.
Talend Data Integration
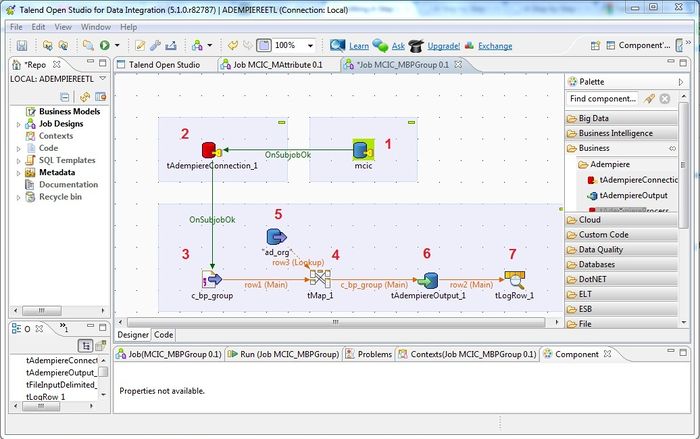
Talend Data Integration — среда для построения конвейеров данных с архитектурой, рассчитанной на масштабирование, гибкость и прозрачный контроль качества. Платформа поддерживает полный цикл работы с данными: извлечение, оркестрацию потоков, управление метаданными, проверку качества и публикацию результатов в корпоративные DWH и облачные среды.
Продуктовая линейка основана на Talend Data Fabric — платформе, объединяющей интеграцию данных, интеграцию приложений и API, управление качеством и доверительным рейтингом, а также управляемый ETL/ELT-конвейер Stitch для быстрых аналитических сценариев. Решения используются в финансовой сфере, здравоохранении, госсекторе, рознице, телеком-индустрии, в задачах распределения, риск-менеджмента, клиентской аналитики 360°, построения облачных озёр и хранилищ. Экосистема партнёров включает Snowflake, AWS, Azure, Google Cloud, Databricks, Cloudera и другие корпоративные интеграции.
Apache Airflow

Apache Airflow — платформа для оркестрации ETL/ELT-процессов, позволяющая управлять зависимостями, расписаниями и автоматизацией больших объёмов задач на Python. Пайплайны описываются на Python, что облегчает интеграцию с любым стеком и позволяет собирать динамические DAG, реагирующие на входные данные или параметры окружения.
Архитектура Airflow масштабируется за счёт распределённых воркеров и очередей сообщений, позволяя обрабатывать от десятков до тысяч задач. Широкая экосистема провайдеров упрощает подключение к AWS, GCP, Azure, объектным хранилищам, Hadoop, SQL-базам и системам обработки событий.
Airflow активно применяют для ETL/ELT-конвейеров, ML-оркестрации, обновления витрин в DWH (Data Warehouse). Подход остаётся универсальным: DAG можно адаптировать под потоковые сценарии, батчевые загрузки, распределённые вычисления или гибридные пайплайны.
Modus ETL

Modus ETL — российское решение для автоматизированного сбора и обработки данных из корпоративных систем: ERP, CRM, HRM, WMS, 1С и различных СУБД. Визуальный интерфейс WorkFlow позволяет настраивать операции верификации, стандартизации, категоризации и трансформации данных без программирования. Полученные данные приводятся к единому виду и загружаются в корпоративное хранилище данных, поддерживаемое MS SQL, PostgreSQL и Vertica.
Сбор информации из 1С возможен через нативные методы (1С/СКД-запросы) или через адаптер ETL-1С, который безопасно извлекает данные, включая возможность обезличивания персональных данных. Модуль «Агент ETL» обеспечивает многопоточное получение данных с управлением очередями, а библиотека драйверов и коннекторов позволяет подключаться к MS SQL, PostgreSQL, Oracle, ClickHouse, Vertica, Greenplum и другим источникам через ODBC.
Дополнительно Modus ETL предлагает визуальные диаграммы для настройки ETL-пакетов, контроль процессов через понятный интерфейс, ER-диаграммы для моделей данных и шаблоны ETL-процессов по очистке, обогащению и верификации информации.
Где используются ETL-процессы
ETL обеспечивает упорядоченное перемещение и интеграцию данных из разнообразных источников в целевые системы. Эти процессы позволяют консолидировать информацию из баз данных, файловых хранилищ, облачных сервисов и корпоративных приложений, формируя готовую к аналитике структуру для DWH, OLAP-систем, отчетности и проектов с большими данными.
Базы данных
Базы данных — одно из ключевых направлений применения ETL. При постоянном потоке данных из разных систем (продажи, CRM, логистика и др.) ETL помогает привести их к единому формату, очистить и загрузить в базу или репозиторий таким образом, чтобы структура и типы данных всегда соответствовали заданным требованиям. Особенно важно, когда множество источников — тогда без ETL легко получить «грязные» или несовместимые данные.
ETL необходим не только при разовой миграции — это постоянный механизм поддержки целостности и качества данных. Процесс извлечения, трансформации и загрузки обеспечивают автоматизированное обновление, согласование форматов, очистку и нормализацию. В результате база остаётся актуальной, пригодной для аналитики, отчётов и интеграций, даже если источники регулярно меняются.
Data Warehouse (DWH)
DWH (Data Warehouse) — это централизованное хранилище, куда поступают данные из разных источников, чтобы обеспечить их готовность для аналитики и отчетности. ETL-процессы в DWH отвечают за извлечение информации из систем 1С, внешних БД, файлов и веб-сервисов, её трансформацию и загрузку в единое хранилище.

Конвейер Data Warehouse
Трансформация данных в DWH включает объединение, нормализацию, фильтрацию и агрегацию, чтобы информация стала однородной и готовой к анализу. Исторические данные сохраняются для построения аналитических витрин и отслеживания динамики бизнес-процессов.
В DWH ETL-конвейеры позволяют создавать витрины данных для различных направлений бизнеса: финансы, продажи, персонал, производство. Конфигурация ETL обеспечивает автоматическое объединение данных из разных систем и организаций, стандартизацию справочников и классификаторов, включая MDM.
OLAP и OLTP
ETL играет роль связующего звена между системами OLTP и OLAP. Эти системы обслуживают разные задачи, но вместе обеспечивают полное управление данными.
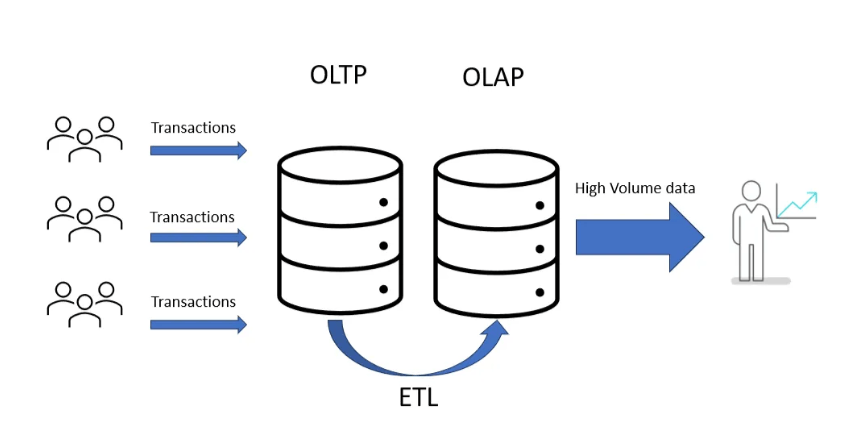
Конвейер OLTP и OLAP
- OLTP (Online Transaction Processing) — системы для обработки большого числа небольших транзакций в реальном времени. Обеспечивают быстрые вставки, обновления и удаление данных с сохранением их целостности. Примеры: банковские переводы, онлайн-заказы, регистрация пользователей.
- OLAP (Online Analytical Processing) — системы для аналитической обработки больших объёмов данных. Позволяют строить сложные отчёты, выполнять многомерный анализ и агрегировать показатели для поддержки бизнес-решений. Не предназначены для потоковых транзакций, но эффективно справляются с масштабными аналитическими запросами.
ETL переносит данные из OLTP в OLAP, преобразуя их в нужный формат: очищает, агрегирует и стандартизирует. В результате бизнес-аналитики получают готовую к работе информацию без риска повредить оперативные транзакции.
Большие данные (Big Data)
Большие данные (Big Data) — работа с огромными объёмами информации требует перемещения данных между системами и их предварительной подготовки.
Процесс ETL для Big Data включает сбор данных из множества источников, стандартизацию и очистку, а затем загрузку в хранилище или Data Lake. Так данные становятся доступными для анализа, построения отчётов и прогнозирования, превращая разрозненные потоки информации в ценный ресурс.
Аналитика
ETL лежит в основе всех видов аналитики — бизнес-, маркетинговой, финансовой и операционной. Он объединяет данные из разных источников, очищает и трансформирует их, превращая разрозненную информацию в структуру, пригодную для анализа, выявления закономерностей и построения прогнозных моделей.
В аналитике ETL превращается в фундамент для построения отчетов, дашбордов и моделей прогнозирования. Специалисты используют его для глубокого понимания процессов и принятия обоснованных решений на основе согласованных данных.
Облачные технологии
Серверы, сервисы и инструменты в облаке (SaaS) заменяют локальные решения, позволяя компаниям хранить и обрабатывать данные удалённо. ETL особенно востребован при миграции больших объёмов информации из локальных систем в облачные хранилища, а также при регулярной интеграции новых потоков данных из разных источников.
IoT
IoT (Internet of Things) — это сеть, объединяющая «умные» устройства, которые могут обмениваться данными и взаимодействовать друг с другом без постоянного участия человека. Устройства собирают информацию с датчиков, передают её по сети и принимают решения на основе полученных данных.
ETL играет важную роль в IoT, помогая интегрировать данные с множества устройств в централизованное хранилище для анализа и отчётности. Данные из сенсоров проходят извлечение, трансформацию и загрузку, чтобы их можно было использовать для мониторинга, прогнозирования и оптимизации работы «умных» систем.
Машинное обучение (ML)
Машинное обучение (ML) — направление, где алгоритмы анализируют большие массивы данных, выявляют закономерности и строят прогнозы. Данные поступают из разных источников и требуют очистки и стандартизации, чтобы модели могли работать с ними корректно.
ETL интегрирует разрозненные данные в единое хранилище или Data Lake, упорядочивает их и готовит для обучения моделей. Именто позволяет формировать качественные датасеты, ускоряет эксперименты с алгоритмами и повышает точность предсказаний.
Что такое ETL-пайплайн
Современные компании работают с потоками данных, которые поступают из десятков независимых систем. Аналитические и продуктовые команды сталкиваются с тем, что каждый сервис генерирует собственный формат, собственную структуру и собственную частоту обновления. Управлять этим вручную практически невозможно, и эту задачу закрывает ETL-пайплайн — автоматизированный контур, который собирает данные из разных источников, преобразует их по бизнес-правилам и загружает в целевую систему, например, хранилище данных, для последующего анализа.
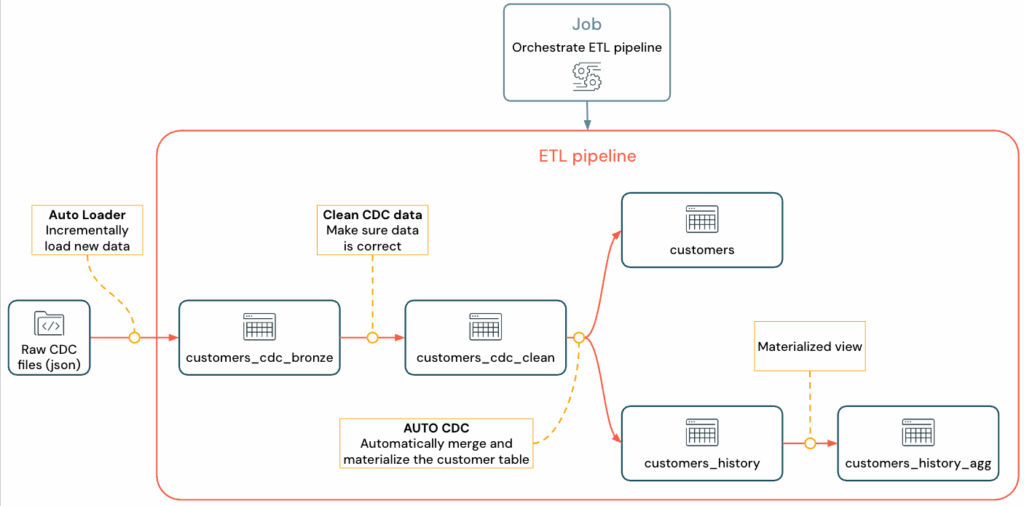
ETL-пайплайн
Корпоративные экосистемы включают транзакционные базы, API внешних сервисов, логирование приложений, телеметрию, стриминговые события. Когда нет общего пайплайна, эти источники начинают «разъезжаться» по структурам и качеству, что приводит к рассинхронизации отчётов, некорректным расчётам и усложнению всей аналитической цепочки.
Пайплайн выстраивает предсказуемый ход обработки: получение данных из источника → техническое и бизнес-преобразование → помещение в хранилище или витрину. Команды получают стабильный маршрут, который устраняет хаотичность интеграций, снижает количество инцидентов и помогает поддерживать актуальность данных в downstream-процессах — сервисов, которые получают данные дальше по потоку (например, BI-отчёты, витрины, операционные панели).
Единый ETL-контур становится не просто техническим компонентом, а организационной основой всей аналитики. Чем чище и стабильнее пайплайн, тем быстрее компания выводит продукты, проверяет гипотезы и масштабирует свои решения.
Поддержка пайплайна превращается в самостоятельную инженерную область: разработчики настраивают адаптеры под источники, проектируют трансформации, контролируют задержки, следят за качеством и SLA. Слаженная работа этих участков формирует тот самый контур, который удерживает корпоративные данные в стройной системе и обеспечивает бизнесу целостную картину происходящего.
Разработка ETL-процессов
Разработка ETL-процессов представляет собой проектирование и построение автоматизированного контура обработки данных. Основная цель — обеспечить стабильную интеграцию и качество информации, чтобы аналитические и бизнес-системы получали данные без ручного вмешательства.
Работа с ETL требует системного подхода и чёткой структуры:
- Анализ источников и требований: разработчик оценивает, какие данные нужны бизнесу, как они организованы в источниках, и какие преобразования потребуются.
- Проектирование трансформаций: создаются логические модели обработки, учитываются правила очистки, нормализации и обогащения данных, формируются зависимости между таблицами и потоками.
- Настройка интеграций: разработчик ETL подключает источники и целевые системы, создаёт адаптеры и контролирует корректность передачи данных.
- Тестирование и отладка: проверяется полнота и качество данных, корректность бизнес-преобразований, выявляются и устраняются ошибки до запуска в продуктив.
- Мониторинг и поддержка: внедряются механизмы логирования, уведомления о сбоях и контроль SLA, чтобы процессы работали стабильно и предсказуемо.
Результат грамотной разработки ETL — надежный, воспроизводимый контур данных, который позволяет командам аналитики и продуктовым сервисам быстро реагировать на изменения, масштабировать решения и минимизировать риски ошибок.
Инструменты ETL
Инструменты ETL используются разработчиками для автоматизации сбора, преобразования и загрузки данных — от небольших интеграций до высоконагруженных корпоративных контуров. Для разных задач применяются разные подходы: корпоративные платформы, облачные сервисы, open-source-решения или полностью кастомные разработки, собранные под конкретные требования.
В экосистеме сформировались четыре основных типа ETL-инструментов. Их развивают разные компании и сообщества, поэтому архитектура, набор возможностей, управляемость и способы масштабирования в каждой категории заметно отличаются.
Для корпоративного ПО
ETL-инструменты корпоративного ПО ориентированы на стабильную работу и полный комплект функций, который покрывает требования крупных организаций. Под такие решения выделяют бессерверные облачные среды, где разработчики собирают и обслуживают процессы через удобные графические интерфейсы. Многие платформы поддерживают не только классическую пакетную обработку, но и потоковые источники, что важно для финансовых систем, логистики и высоконагруженных веб-проектов.
В этом сегменте работают проверенные решения, о которых уже шла речь: Informatica PowerCenter, Microsoft SISS, Talend Data Integration и другие корпоративные интеграционные платформы. Каждая из них даёт доступ к готовым коннекторам, встроенной оптимизации, управляющим консолям и механизмам мониторинга. Разработчикам остаётся сосредоточиться на логике и качестве данных, не тратя время на инфраструктурные задачи.
Большинство корпоративных ETL-решений предоставляют соглашения об уровне обслуживания (SLA), поэтому компании получают предсказуемую производительность, поддержку и гарантии стабильной работы. Такая модель особенно выгодна в проектах, где задержки в обновлении данных могут нарушить работу аналитических витрин, отчётности и прикладных сервисов.
Облачные (SaaS)
Облачные (SaaS) ETL-инструменты предлагают готовую среду для интеграции данных внутри инфраструктуры Amazon Web Services, Google Cloud и Microsoft Azure. Такие сервисы встроены в экосистему облачных поставщиков и используют их нативные механизмы безопасности масштабирования и хранения. Интеграция с корпоративными решениями упрощается за счёт готовых коннекторов, сервисных ролей и автоматического управления ресурсами.
Существуют и SaaS-платформы ETL, которые работают поверх разных облаков и подключаются к гетерогенным средам. Эти решения объединяют источники, хранилища и аналитические сервисы в единый рабочий процесс без необходимости писать код. Визуальные дизайнеры, готовые шаблоны и библиотеки трансформаций позволяют специалистам быстрее собирать сложные маршруты обработки.
Ограничением облачных ETL остаётся отсутствие поддержки локальных ЦОД, если такая интеграция не предусмотрена в рамках бэкап- или гибридных сценариев. Основная логика работы ориентирована на облачные хранилища, распределённые вычисления и сервисные API, поэтому компании с полностью он-прем средой рассматривают гибридные подходы или переходят на инструменты, предназначенные для локальной инфраструктуры.
С открытым исходным кодом (Open-source)
ETL-инструменты с открытым исходным кодом, такие как Apache Airflow или Talend Open Studio создаются сообществом разработчиков и предоставляют полный доступ к исходному коду по open-source лицензиям (Apache License 2.0, GPL, LGPL, MIT). Их можно модифицировать под специфические задачи, расширять функциональность и интегрировать в корпоративные процессы.
Инструменты с открытым исходным кодом предоставляют удобный интерфейс для построения и эксплуатации конвейеров данных, однако отсутствие официальной коммерческой поддержки может сказываться на стабильности и качестве работы. Настройка и эксплуатация требуют опытного разработчика, способного обеспечить масштабируемость, безопасность и соответствие бизнес-требованиям.
Пользовательские
Пользовательские ETL-инструменты разрабатываются с нуля под конкретные задачи компании, используя SQL, Python, Java и другие технологии. Они позволяют точно соответствовать внутренним требованиям, интегрироваться с уникальными источниками данных и учитывать особенности бизнес-процессов.
Создание таких инструментов требует опытной команды разработчиков: нужно спроектировать процессы, подготовить документацию, протестировать производительность и обеспечить безопасность. В результате организация получает максимально адаптированные пайплайны, которые полностью контролируют поток данных и поддерживают высокое качество информации для аналитики и продуктов.
ETL и ELT: в чём разница?
ETL (Extract, Transform, Load) и ELT (Extract, Load, Transform) — процессы обработки данных, используемые в аналитике и управлении корпоративными данными. ETL извлекает данные из источников, выполняет их трансформацию (очистка, нормализация, объединение) и затем загружает в целевую систему для анализа. ELT меняет порядок действий: данные сначала загружаются в целевую систему в исходном виде, а преобразования выполняются уже внутри этой системы с использованием её вычислительных ресурсов.

ELT — более новый подход по сравнению с ETL, поскольку он сразу загружает сырые данные и лучше подходит для больших объемов данных в облачных хранилищах. Современные облачные платформы и инструменты делают ELT предпочтительным вариантом для анализа больших и разнообразных массивов данных.
Ключевые отличия ETL и ELT можно охарактеризовать так:
- Порядок трансформации данных — ETL сначала преобразует данные, затем загружает (Extract→ Transform → Load); ELT сначала загружает, затем преобразует (Extract → Load → Transform).
- Объём обрабатываемых данных — ELT справляется с большими потоками, ETL с меньшими и средними.
- Работа с неструктурированными данными — ELT позволяет загружать в хранилище как структурированные, так и неструктурированные данные, в отличие от ETL.
Читайте подробнее: ETL и ELT: что это, чем отличаются, что лучше выбрать
Заключение
ETL формирует структурированные потоки данных, объединяя разрозненные источники и обеспечивая их готовность к аналитике, отчётности и прикладным сервисам. Автоматизация таких процессов обеспечивает стабильное извлечение, трансформацию и загрузку данных, снижает вероятность ошибок и поддерживает корректность downstream-процессов, делая обработку информации предсказуемой и воспроизводимой. Однако при всём этом, проектирование ETL требует от разработчика внимательного анализа источников, продуманной логики трансформаций и постоянного контроля качества.
Инструменты ETL различаются по функционалу, доступности и масштабу: корпоративные платформы обеспечивают стабильную обработку больших объёмов, облачные SaaS-сервисы ускоряют интеграцию и масштабирование, open-source и кастомные разработки дают гибкость для уникальных задач. ETL связывает системы OLTP и OLAP, подготавливает данные для аналитики, Big Data, IoT и ML, обеспечивая удобный доступ к качественной информации.
Выбор между ETL и ELT зависит от объёмов данных и требований к скорости обработки: ETL удобен для малых и средних потоков, ELT лучше подходит для больших массивов и гибких аналитических сценариев.